
ADMIN
FAQ
Developer documentation is here.A work-in-progress comparison to SOLR.
Table of Contents
Quick Start
Build from Source
Features
API - for doing searches, indexing documents and performing cluster maintenance
Hardware Requirements - what is required to run gigablast
Performance Specifications - various statistics.
Screenshots
Setting up a Cluster - how to run multiple gb instances in a sharded cluster.
Scaling the Cluster - how to add more gb instances.
Updating the Binary - follow similar procedure to Scaling the Cluster
Cleaning Up after a Crash - how do i make sure my data is in tact after a host crashes?
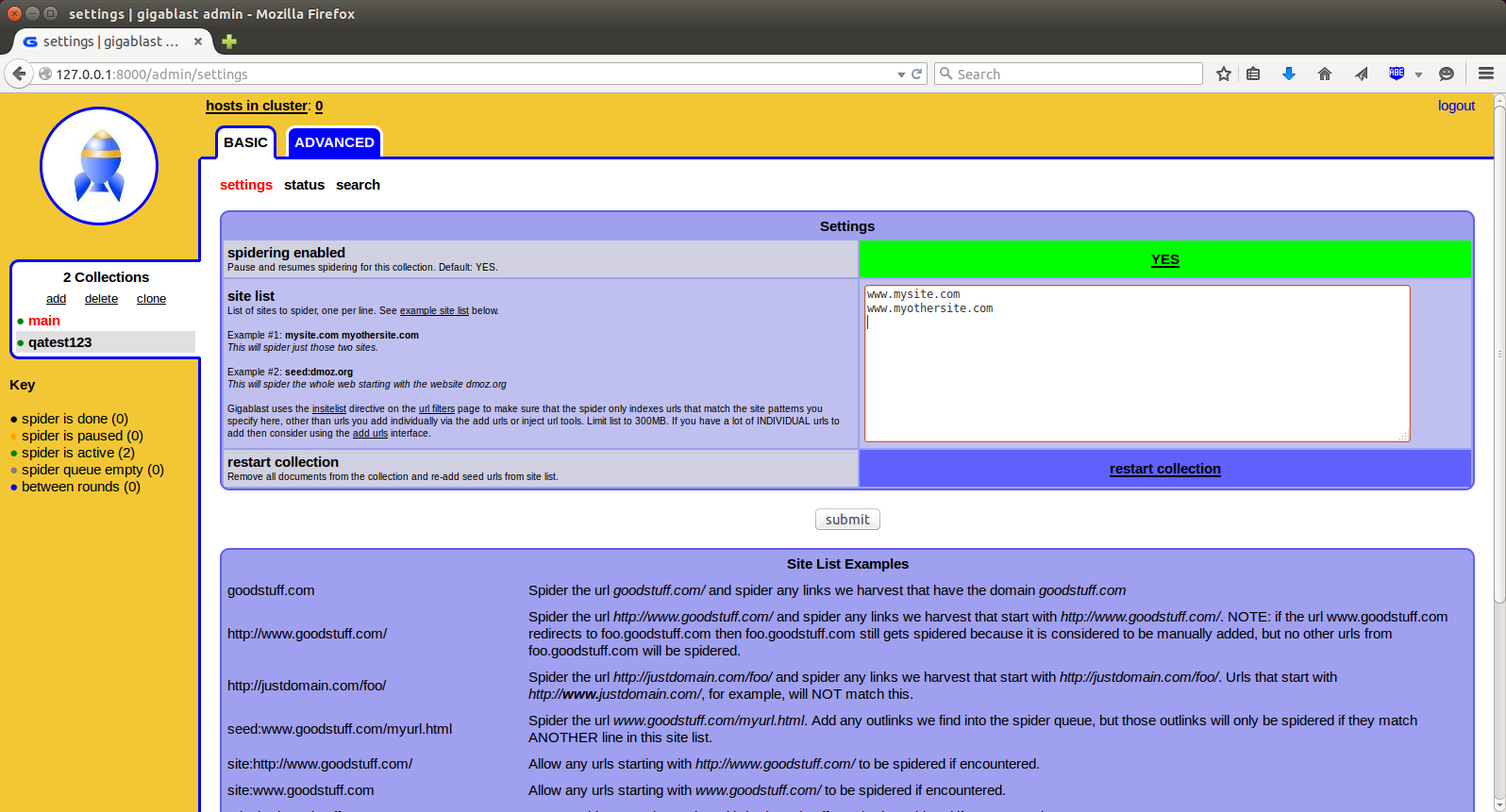
The Spider - how does the spider work?
Command Line Options - various command line options (coming soon)
Injecting Documents - inserting documents directly into Gigablast
Deleting Documents - removing documents from the index
Indexing User-Defined Meta Tags - how Gigablast indexes user-defined meta tags
Building a DMOZ Based Directory - build a web directory based on open DMOZ data
The Log System - how Gigablast logs information
Optimizing - optimizing Gigablast's spider and query performance
Quick Start
<Last Updated February 2015>Requirements:
You will need an Intel or AMD system with at least 4GB of RAM for every gigablast shard you want to run.
For Debian/Ubuntu Linux:
1. Download a package: Debian/Ubuntu 64-bit ( Debian/Ubuntu 32-bit )
2. Install the package by entering: sudo dpkg -i <filename> where filename is the file you just downloaded.
3. Type sudo gb -d to run Gigablast in the background as a daemon.
4. If running for the first time, it could take up to 20 seconds to build some preliminary files.
5. Once running, visit port 8000 with your browser to access the Gigablast controls.
6. To list all packages you have installed do a dpkg -l.
7. If you ever want to remove the gb package type sudo dpkg -r gb.
For RedHat/Fedora Linux:
1. Download a package: RedHat 64-bit ( RedHat 32-bit )
2. Install the package by entering: rpm -i --force --nodeps <filename> where filename is the file you just downloaded.
3. Type sudo gb -d to run Gigablast in the background as a daemon.
4. If running for the first time, it could take up to 20 seconds to build some preliminary files.
5. Once running, visit port 8000 with your browser to access the Gigablast controls.
For Microsoft Windows:
1. If you are running Microsoft Windows, then you will need to install Oracle's VirtualBox for Windows hosts software. That will allow you to run Linux in its own window on your Microsoft Windows desktop.
2. When configuring a new Linux virtual machine in VirtualBox, make sure you select at least 4GB of RAM.
3. Once VirtualBox is installed you can download either an Ubuntu CD-ROM Image (.iso file) or a Red Hat Fedora CD-ROM Image (.iso file). The CD-ROM Images represent Linux installation CDs.
4. When you boot up Ubuntu or Fedora under VirtualBox for the first time, it will prompt you for the CD-ROM drive, and it will allow you to enter your .iso filename there.
5. Once you finish the Linux installation process and then boot into Linux through VirtualBox, you can follow the Linux Quick Start instructions above.
| Installed Files | |
| Directory of Gigablast binary and data files | |
| /etc/init.d/gb | start up script link |
| /usr/bin/gb | Link to /var/gigablast/data0/gb |
Build From Source
<Last Updated January 2015>Requirements: You will need an Intel or AMD system running Linux and at least 4GB of RAM.
1.0 For Ubuntu 12.02 or 14.04: do sudo apt-get update ; sudo apt-get install make g++ libssl-dev binutils
1.1. For RedHat do sudo yum install gcc-c++
2. Download the Gigablast source code using wget --no-check-certificate "https://github.com/gigablast/open-source-search-engine/archive/master.zip", unzip it and cd into it. (optionally use git clone https://github.com/gigablast/open-source-search-engine.git ./github if you have git installed.)
3.0 Run make to compile. (e.g. use 'make -j 4' to compile on four cores)
3.1 If you want to compile a 32-bit version of gb for some reason, run make clean ; make gb32.
4. Run ./gb -d to start a single gigablast node which listens on port 8000 running in daemon mode (-d).
5. The first time you run gb, wait about 30 seconds for it to build some files. Check the log file to see when it completes.
6. Go to the root page to begin.
Features
<Last Updated Jan 2015>- The ONLY open source WEB search engine.
- 64-bit architecture.
- Scalable to thousands of servers.
- Has scaled to over 12 billion web pages on over 200 servers.
- A dual quad core, with 32GB ram, and two 160GB Intel SSDs, running 8 Gigablast instances, can do about 8 qps (queries per second) on an index of 10 million pages. Drives will be close to maximum storage capacity. Doubling index size will more or less halve qps rate. (Performance metrics can be made about ten times faster but I have not got around to it yet. Drive space usage will probably remain about the same because it is already pretty efficient.)
- 1 million web pages requires 28.6GB of drive space. That includes the index, meta information and the compressed HTML of all the web pages. That is 28.6K of disk per HTML web page.
- Spider rate is around 1 page per second per core. So a dual quad core can spider and index 8 pages per second which is 691,200 pages per day.
- 4GB of RAM required per Gigablast instance. (instance = process)
- Live demo at http://www.gigablast.com/
- Written in C/C++ for optimal performance.
- Over 500,000 lines of C/C++.
- 100% custom. A single binary. The web server, database and everything else is all contained in this source code in a highly efficient manner. Makes administration and troubleshooting easier.
- Reliable. Has been tested in live production since 2002 on billions of queries on an index of over 12 billion unique web pages, 24 billion mirrored.
- Super fast and efficient. One of a small handful of search engines that have hit such big numbers. The only open source search engine that has.
- Supports all languages. Can give results in specified languages a boost over others at query time. Uses UTF-8 representation internally.
- Track record. Has been used by many clients. Has been successfully used in distributed enterprise software.
- Cached web pages with query term highlighting.
- Shows popular topics of search results (Gigabits), like a faceted search on all the possible phrases.
- Email alert monitoring. Let's you know when the system is down in all or part, or if a server is overheating, or a drive has failed or a server is consistently going out of memory, etc.
- "Synonyms" based on wiktionary data. Using query expansion method.
- Customizable "synonym" file: my-synonyms.txt
- No silly TF/IDF or Cosine. Stores position and format information (fancy bits) of each word in an indexed document. It uses this to return results that contain the query terms in close proximity rather than relying on the probabilistic tf/idf approach of other search engines.
- Complete scoring details are displayed in the search results.
- Indexes anchor text of inlinks to a web page and uses many techniques to flag pages as link spam thereby discounting their link weights.
- Demotes web pages if they are spammy.
- Can cluster results from same site.
- Duplicate removal from search results.
- Distributed web crawler/spider. Supports crawl delay and robots.txt.
- Crawler/Spider is highly programmable and URLs are binned into priority queues. Each priority queue has several throttles and knobs.
- Spider status monitor to see the urls being spidered over the whole cluster in a real-time widget.
- Complete REST/XML API for doing queries as well as adding and deleting documents in real-time.
- Automated data corruption detection, fail-over and repair based on hardware failures.
- Custom Search. (aka Custom Topic Search). Using a cgi parm like &sites=abc.com+xyz.com you can restrict the search results to a list of up to 500 subdomains.
- DMOZ integration. Run DMOZ directory. Index and search over the pages in DMOZ. Tag all pages from all sites in DMOZ for searching and displaying of DMOZ topics under each search result.
- Collections. Build tens of thousands of different collections, each treated as a separate search engine. Each can spider and be searched independently.
- Federated search over multiple Gigablast collections using syntax like &c=mycoll1+mycoll2+mycoll3+...
- Plug-ins. For indexing any file format by calling Plug-ins to convert that format to HTML. Provided binary plug-ins: pdftohtml (PDF), ppthtml (PowerPoint), antiword (MS Word), pstotext (PostScript).
- Indexes JSON and XML natively. Provides ability to search individual structured fields.
- Sorting. Sort the search results by meta tags or JSON fields that contain numbers, simply by adding something like gbsortby:price or gbrevsortby:price as a query term, assuming you have meta price tags.
- Easy Scaling. Add new servers to the hosts.conf file then click 'rebalance shards' to automatically rebalance the sharded data.
- Using &stream=1 can stream back millions of search results for a query without running out of memory.
- Makes and displays thumbnail images in the search results.
- Nested boolean queries using AND, OR, NOT operators.
- Built-in support for diffbot.com's api, which extracts various entities from web sites, like products, articles, etc. But you will need to get a free token from them for access to their API.
- Facets over meta tags or X-Paths for HTML documents.
- Facets over JSON and XML fields.
- Sort and constrain by numeric fields in JSON or XML.
- Built-in real-time profiler.
- Built-in QA tester.
- Can inject WARC and ARC archive files.
<Last Updated January 2014>
At least one computer with 4GB RAM, 10GB of hard drive space and any distribution of Linux with the 2.4.25 kernel or higher. For decent performance invest in Intel Solid State Drives. I tested other brands around 2010 and found that they would freeze for up for 500ms every hour or so to do "garbage collection". That is unacceptable in general for a search engine. Plus, Gigablast, reads and writes a lot of data at the same time under heavy spider and query loads, therefore disk will probably be your MAJOR bottleneck.
<Last Updated January 2014>
Gigablast can store 100,000 web pages (each around 25k in size) per gigabyte of disk storage. A typical single-cpu pentium 4 machine can index one to two million web pages per day even when Gigablast is near its maximum document capacity for the hardware. A cluster of N such machines can index at N times that rate.
<Last Updated April 2015>
<Last Updated July 2014>
1. Locate the hosts.conf file. If installing from binaries it should be in the /var/gigablast/data0/ directory. If it does not exist yet then run gb or ./gb which will create one. You will then have to exit gb after it does.
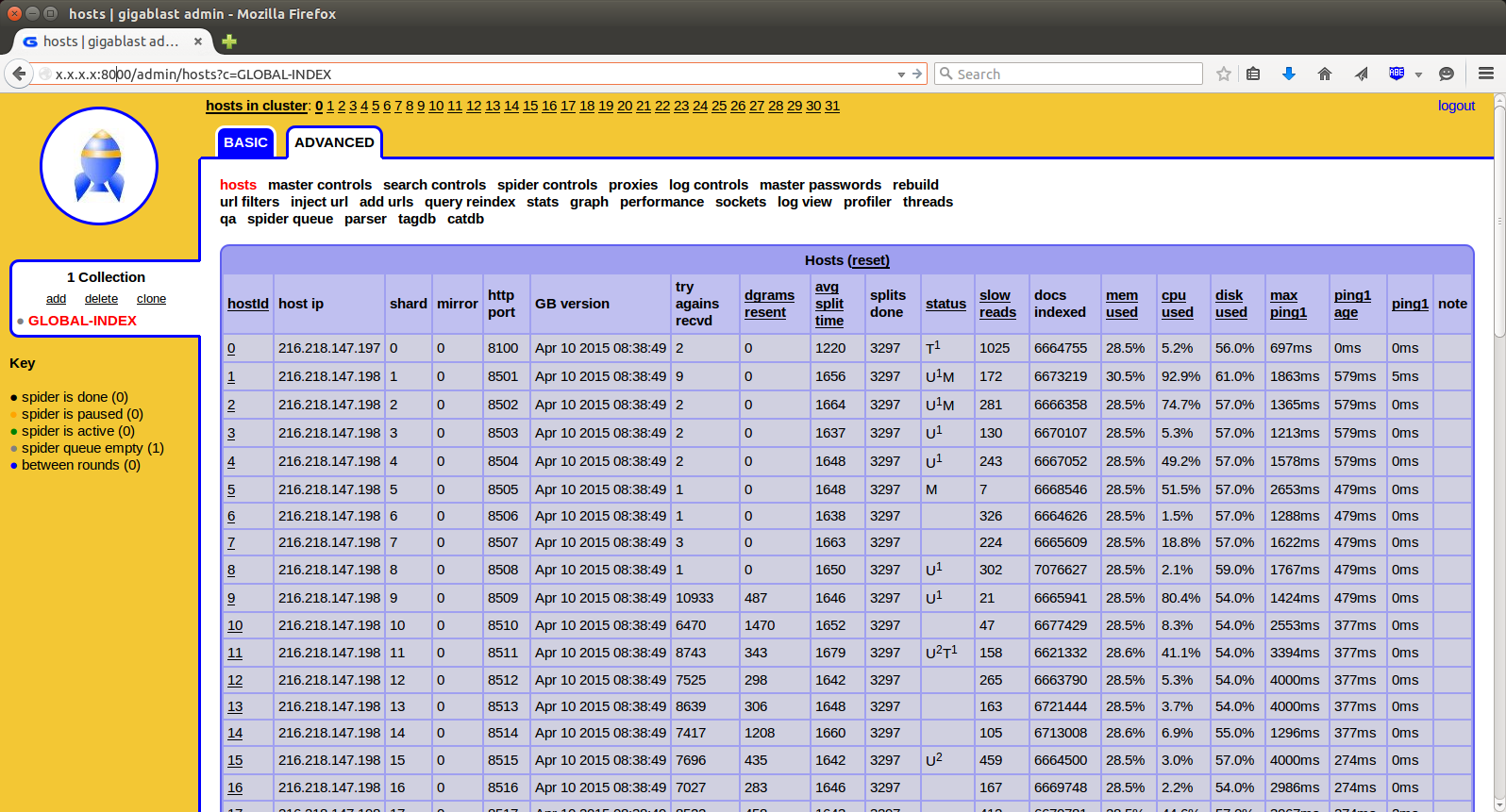
2. Update the num-mirrors in the hosts.conf file. Leave it as 0 if you do not want redundancy. If you want each shard to be mirrored by one other gb instance, then set this to 1. I find that 1 is typically good enough, provided that the mirror is on a different physical server. So if one server gets trashed there is another to serve that shard. The sole advantage in not mirroring your cluster is that you will have twice the disk space for storing documents. Query speed should be unaffected because Gigablast is smart enough to split the load evenly between mirrors when processing queries. You can send your queries to any shard and it will communicate with all the other shards to aggregate the results. If one shard fails and you are not mirroring then you will lose that part of the index, unfortunately.
3. Make one entry in the hosts.conf per physical core you have on your server. If an entry is on the same server as another, then it will need a completely different set of ports. Each gb instance also requires 4GB of ram, so you may be limited by your RAM before being limited by your cores. You can of course run multiple gb instances on a single core if you have the RAM, but performance will not be optimal.
4. Continue following the instructions for Scaling the Cluster below in order to get the other shards set up and running.
<Last Updated June 2014>
1. If your spiders are active, then turn off spidering in the master controls.
2. If your cluster is running, shut down the clustering by doing a gb stop command on the command line OR by clicking on "save & exit" in the master controls
3. Edit the hosts.conf file in the working directory of host #0 (the first host entry in the hosts.conf file) to add the new hosts.
4. Ensure you can do passwordless ssh from host #0 to each new IP address you added. This generally requires running ssh-keygen -t dsa on host #0 to create the files ~/.ssh/id_dsa and ~/.ssh/id_dsa.pub. Then you need to insert the key in ~/.ssh/id_dsa.pub into the ~/.ssh/authorized_keys2 file on every host, including host #0, in your cluster. Furthermore, you must do a chmod 700 ~/.ssh/authorized_keys2 on each one otherwise the passwordless ssh will not work.
5. Run gb install <hostid> on host #0 for each new hostid to copy the required files from host #0 to the new hosts. This will do an scp which requires the passwordless ssh. <hostid> can be a range of hostids like 5-12 as well.
6. Run gb start on the command line to start up all gb instances/processes in the cluster.
7. If your index was not empty, then click on rebalance shards in the master controls to begin moving data from the old shards to the new shards. The hosts table will let you know when the rebalance operation is complete. It should be able to serve queries during the rebalancing, but spidering can not resume until it is completed.
<Last Updated Sep 2014>
A host in the network crashed. What is the recovery procedure?
First determine if the host's crash was clean or unclean. It was clean if the host was able to save all data in memory before it crashed. If the log ended with allExit: dumping core after saving then the crash was clean, otherwise it was not.
If the crash was clean then you can simply restart the crashed host by typing gb start i where i is the hostId of the crashed host. However, if the crash was not clean, like in the case of a sudden power outtage, then in order to ensure no data gets lost, you must copy the data of the crashed host's twin. If it does not have a twin then there may be some data loss and/or corruption. In that case try reading the section below, How do I minimize the damage after an unclean crash with no twin?, but you may be better off starting the index build from scratch. To recover from an unclean crash using the twin, follow the steps below:
a. Click on 'all spiders off' in the 'master controls' of host #0, or host #1 if host #0 was the host that crashed.
b. If you were injecting content directly into Gigablast, stop.
c. Click on 'all just save' in the 'master controls' of host #0 or host #1 if host #0 was the one that crashed.
d. Determine the twin of the crashed host by looking in the hosts.conf file or on the hosts page. The twin will have the same shard number as the crashed host.
e. Recursively copy the working directory of the twin to the crashed host using rcp since it is much faster than scp.
f. Restart the crashed host by typing gb start i where i is the hostId of the crashed host. If it is not restartable, then skip this step.
How do I minimize the damage after an unclean crash with no twin?
You may never be able to get the index 100% back into shape right now, but in the near future there may be some technology that allows gigablast to easily recover from these situations. For now though, 2. Try to determine the last url that was indexed and *fully* saved to disk. Every time you index a url some data is added to all of these databases: checksumdb, posdb (index), spiderdb, titledb and clusterdb. These databases all have in-memory data that is periodically dumped to disk. So you must determine the last time each of these databases dumped to disk by looking at the timestamp on the corresponding files in the appropriate collection subdirectories contained in the working directory. If clusterdb was dumped to disk the longest time ago, then use its timestamp to indicate when the last url was successfully added or injected. You might want to subtract thirty minutes from that timestamp to make sure because it is really the time that that file started being dumped to disk that you are after, and that timestamp represents the time of the last write to that file. Now you can re-add the potentially missing urls from that time forward using the AddUrl page and get a semi-decent recovery.
<Last Updated Sep 2014>
Robots.txt
The name of Gigablast's spider is Gigabot, but it by default uses GigablastOpenSource as the name of the User-Agent when downloading web pages. Gigabot respects the robots.txt convention (robot exclusion) as well as supporting the meta noindex, noarchive and nofollow meta tags. You can tell Gigabot to ignore robots.txt files on the Spider Controls page.
Spider Queues
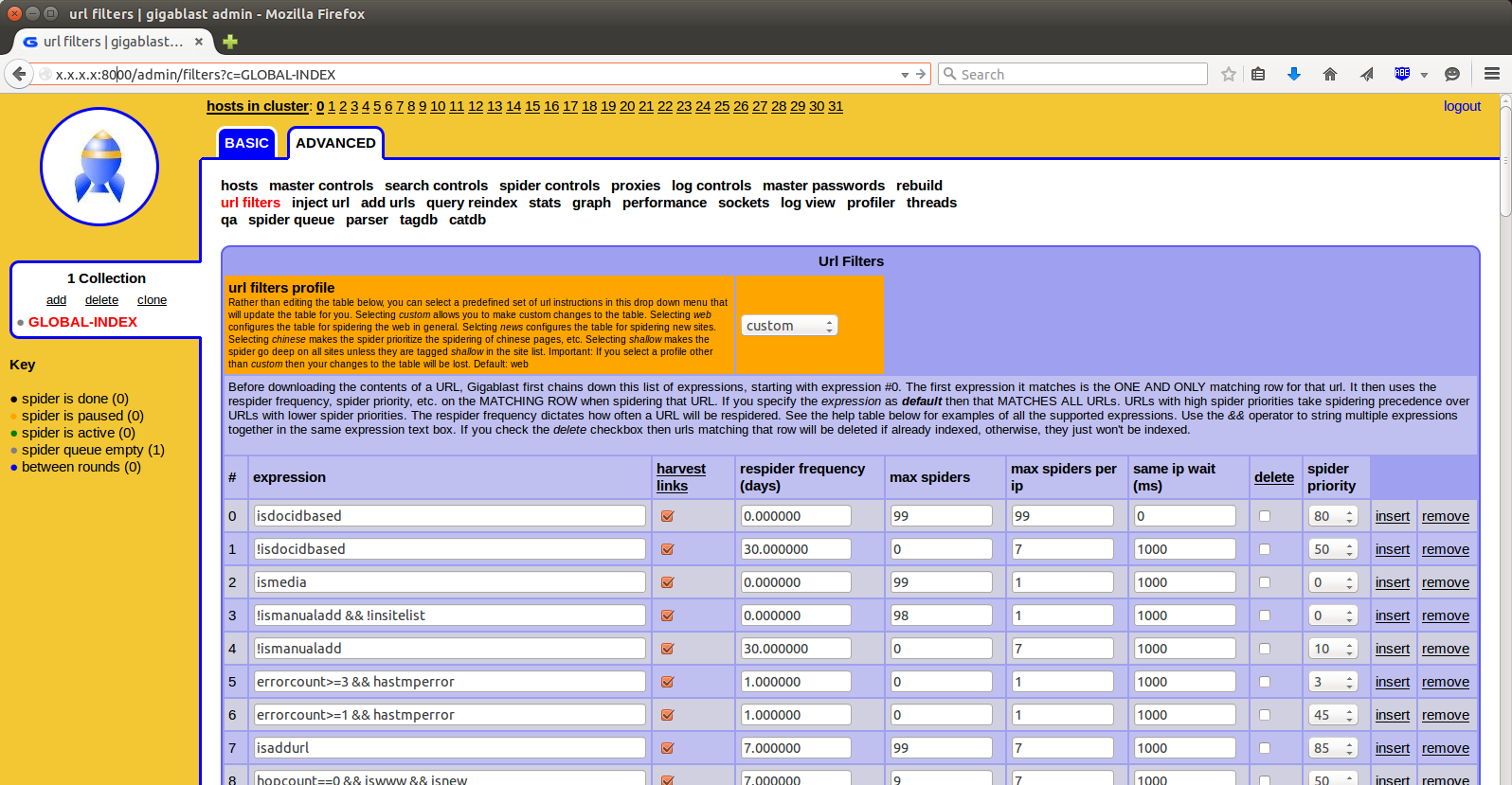
You can tell Gigabot what to spider by using the site list on the Settings page. You can have very precise control over the spider by also employing the use of the URL Filters page which allows you to prioritize and schedule the spiders based on the individual URL and many of its associated attributes, such as hop count, language, parent language, whether is is indexed already and number of inlinks to its site, to name just a smidgen.
<Last Updated Jan 23, 2016>
<Procedure tested on 32-bit Gigablast on Ubuntu 14.04 on Jun 21, 2015>
<Procedure tested on 64-bit Gigablast on Ubuntu 14.04 on Jan 23, 2016>
Building the DMOZ Directory:
- Create the dmozparse program.
$ make dmozparse
- Download the latest content.rdf.u8 and structure.rdf.u8 files from http://rdf.dmoz.org/rdf into the catdb/ directory onto host 0, the first host listed in the hosts.conf file.
$ mkdir catdb
$ cd catdb
$ wget http://rdf.dmoz.org/rdf/content.rdf.u8.gz
$ gunzip content.rdf.u8.gz
$ wget http://rdf.dmoz.org/rdf/structure.rdf.u8.gz
$ gunzip structure.rdf.u8.gz
- Execute dmozparse in its directory with the new option to generate the catdb .dat files. These .dat files are in Gigablast's special format so Gigablast can quickly get all the associated DMOZ entries given a url. Having several Missing parent for catid ... messages are normal. Ultimately, it should put two files into the catdb/ subdirectory: gbdmoz.structure.dat and gbdmoz.content.dat.
$ cd ..
$ ./dmozparse new
- Execute the installcat script command on host 0 to distribute the catdb files to all the hosts.
This just does an scp from host 0 to the other hosts listed in hosts.conf.
$ ./gb installcat
- Make sure all spiders are stopped and inactive.
- Click the catdb in the admin section of Gigablast and click "Generate Catdb" (NOT Update Catdb). This will make a huge list of catdb records and then add them to all the hosts in the network in a sharded manner.
- Once the command returns, typically in 3-4 minutes, Catdb will be ready for use and spidering. It will have created some ./catdb/catdb*.dat files which are Gigablast's database of DMOZ entry records. Any documents added that are from a site in DMOZ will show up in the search results with their appropriate DMOZ categories listed beneath. This will affect all collections.
Testing DMOZ:
- Go to the catdb page and enter a url into the Lookup Category Url box and hit enter to see the associated DMOZ records for that url. So if you enter https://www.ibm.com/ you should see a few entries. It treats http as different from https, so be careful with that because http://www.ibm.com/ is not in it.
Searching DMOZ:
- Gigablast provides the unique ability to search the content of the pages in the DMOZ directory. But in order to search the pages in DMOZ we have to index them. You can't search what is not indexed.
So execute dmozparse with the urldump -s option to create the html/gbdmoz.urls.txt.* files which contain all the URLs in DMOZ. (Excluding URLs that contained hashtags, '#'.) It will create several large files. Each file it creates is basically a VERY LARGE page of links and each link is a url in dmoz. Each of these files has a <meta name=spiderlinkslinks content=0> special Gigablast meta tag that says NOT to follow the links OF THE LINKS. So it will just spider the outlinks on this massive page and then stop. Furthermore, the massive page also has a <meta name=noindex content=1> tag that tells Gigablast to not index this massive page itself, but only spider the outlinks.
$ ./dmozparse urldump -s
- Now tell Gigablast to index each URL listed in each gbdmoz.urls.txt.* file. Make sure you specify the collection you are using for DMOZ, in the example below it uses main. You can use the add url page to add the gbdmoz.urls.txt.* files or you can use curl (or wget) like:
$ curl "http://127.0.0.1:8000/addurl?id=1&spiderlinks=1&c=main&u=http://127.0.0.1:8000/gbdmoz.urls.txt.0"
$ curl "http://127.0.0.1:8000/addurl?id=1&spiderlinks=1&c=main&u=http://127.0.0.1:8000/gbdmoz.urls.txt.1"
$ curl "http://127.0.0.1:8000/addurl?id=1&spiderlinks=1&c=main&u=http://127.0.0.1:8000/gbdmoz.urls.txt.2"
$ curl "http://127.0.0.1:8000/addurl?id=1&spiderlinks=1&c=main&u=http://127.0.0.1:8000/gbdmoz.urls.txt.3"
$ curl "http://127.0.0.1:8000/addurl?id=1&spiderlinks=1&c=main&u=http://127.0.0.1:8000/gbdmoz.urls.txt.4"
$ curl "http://127.0.0.1:8000/addurl?id=1&spiderlinks=1&c=main&u=http://127.0.0.1:8000/gbdmoz.urls.txt.5"
$ curl "http://127.0.0.1:8000/addurl?id=1&spiderlinks=1&c=main&u=http://127.0.0.1:8000/gbdmoz.urls.txt.6"
- Each gbdmoz.urls.txt.* file contains a special meta tag which instructs Gigablast to index each DMOZ URL even if there was some external error, like a DNS or TCP timeout. If the error is internal, like an Out of Memory error, then the document will, of course, not be indexed, but it should be reported in the log. This is essential for making our version of DMOZ exactly like the official version.
- Finally, ensure spiders are enabled for your collection. In the above example, main. And ALSO ensure that spiders are enabled in the Master Controls for all collections. Then the URLs you added above should be spidered and indexed. Hit reload on the Spider Queue tab to ensure you see some spider activity for your collection.
Deleting Catdb:
- Shutdown Gigablast.
- Delete catdb-saved.dat and all catdb/catdb*.dat and catdb/catdb*.map files from all hosts.
- Start Gigablast.
- You will have to run ./dmozparsenew new again to undelete.
Troubleshooting:
- Dmozparse prints an error saying it could not open a file:
Be sure you are running dmozparse in the cat directory and that the steps above have been followed correctly so that all the necessary files have been downloaded or created.
- Dmozparse prints an Out of Memory error:
Some modes of dmozparse can require several hundred megabytes of system memory. Systems with insufficient memory, under heavy load, or lacking a correctly working swap may have problems running dmozparse. Attempt to free up as much memory as possible if this occcurs.
- How to tell if pages are being added with correct directory data:
All pages with directory data are indexed with special terms utilizing a prefix and sufix. The prefixes are listed below and represent a specific feature under which the page was indexed. The sufix is always a numerical category ID. To search for one of these terms, simply performa a query with "prefix:sufix", i.e. "gbpcat:2" will list all pages under the Top category (or all pages in the entire directory).
- gbcatid - The page is listed directly under this base category.
- gbpcatid - The page is listed under this category or any child of this category.
- gbicatid - The page is listed indirectly under this base category, meaning it is a page found under a site listed in the base category.
- gbipcatid - The page is listed indirectly under this category, meaning it is a page found under a site listed under this category or any child of this category.
- gbcatid - The page is listed directly under this base category.
- Pages are not being indexed with directory data:
First check to make sure that sites that are actually in DMOZ are those being added by the spiders. Next check to see if the sites return category information when looked up under the Catdb admin section. If they come back with directory information, the site may just need to be respidered. If the lookup does not return category information and all hosts are properly running, Catdb may need to be rebuilt from scratch.
- The Directory shows results but does not show sub-category listings or a page error is returned and no results are shown:
Make sure the gbdmoz.structure.dat and structure.rdf.u8 files are in the cat directory on every host. Also be sure the current dat files were built from the current rdf.u8 files. Check the log to see if Categories was properly loaded from file at startup (grep log# Categories).
<Last Updated March 2014>
Gigablast uses its own format for logging messages, for example,1091228736104 0 Gigablast Version 1.234 1091228736104 0 Allocated 435333 bytes for thread stacks. 1091228736104 0 Failed to alloc 360000 bytes. 1091228736104 0 Failed to intersect lists. Out of memory. 1091228736104 0 Too many words. Query truncated. 1091228736104 0 GET http://hohum.com/foobar.html 1091228736104 0 http://hohum.com/foobar.html ip=4.5.6.7 : Success 1091228736104 0 Skipping xxx.com, would hammer IP.The first field, a large number, is the time in milliseconds since the epoch. This timestamp is useful for evaluating performance. The second field, a 0 in the above example, is the hostId (from hosts.conf) of the host that logged the message. The last field, is the message itself. You can turn many messages on and off by using the Log Controls. The same parameters on the Log Controls page can be adjusted in the gb.conf file. <Last Updated Sep 2014> Gigablast is a fairly sophisticated database that has a few things you can tweak to increase query performance or indexing performance. General Optimizations:
Query Optimizations:
Spidering and Indexing Optimizations:
|